Published by xi on 2011-05-10
SQL was invented with a promise of opening data access to people who are not professional programmers – but ended up as an arcane art for database experts. This transformation didn’t go unnoticed, but the reason why writing SQL queries is so hard was never properly explained.
Frustration on usage of SQL often expressed as complains about its bulky syntax, inconsistent semantics, and occasionally about SQL violating the relational model.
I believe the problem of SQL, and relational model in general, is that it does not respect the structure of business requests. takes a form of complains
Writing an analytical SQL query starts with a business inquiry, an textual description of the required data. The inquiry could be formulated by a business user or a programmer. The programmer then translated the inquiry to a query language.
Often, in the process of database audit or refactoring, it is necessary to update existing SQL queries. To verify correctness of an existing SQL query, we need to extract the original business inquiry from the SQL.
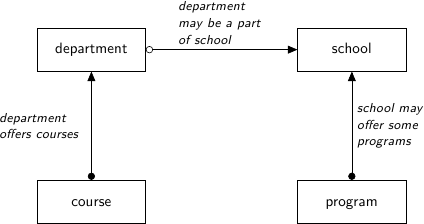
In the examples below, we will use a fragment of a database for student enrollment system. This database contains four tables:
| code | name | campus |
|---|---|---|
| art | School of Art & Design | old |
| bus | School of Business | south |
| edu | College of Education | old |
| code | name | school_code |
|---|---|---|
| acc | Accounting | bus |
| arthis | Art History | la |
| astro | Astronomy | ns |
| school_code | code | title | degree | part_of_code |
|---|---|---|---|---|
| art | gart | Post Baccalaureate in Art History | pb | |
| art | uhist | Bachelor of Arts in Art History | ba | |
| art | ustudio | Bachelor of Arts in Studio Art | ba | |
| department_code | no | title | credits | description |
|---|---|---|---|---|
| acc | 100 | Practical Bookkeeping | 2 | |
| acc | 200 | Introduction to Accounting | 3 | The initial course in the theory and practice of financial accounting. Topics emphasized include the preparation, reporting, and analysis of financial data. |
| acc | 234 | Accounting Information Systems | 3 | This course bridges the gap between two disciplines critical to business operations. This course of study teaches students to design and deploy information technology to improve the accounting systems of an organization. |
The database contains schools, departments associated with a school, programs administered by a school, and courses offered by a department.
Against this schema, we could ask a number of business inquiries:
From the above examples, you can see that a well-defined business inquiry usually has a fixed form (or could be reduced to this form):
For each row of ...
such that ...
give me
1) ...
2) ...
In this form, we see a sentence of a business inquiry clearly splits into three parts: selection of the record set (for each row of ...) filtering on the record set (such that ...) and choosing columns to output (give me 1) ..., 2) ...,). I believe SQL is confusing and hard to use for many people because it does not respect well this separation.
On the first sight, it is completely wrong, and indeed a canonical form of a SQL query is:
SELECT ...
FROM ...
WHERE ...
This form shows that business request clearly separate selection of the row set (schools, departments, etc) and selection of the columns to output (school name, number of courses, etc). I believe SQL is confusing and hard to use for many people because it does not respect this separation.
On the first sight, it is wrong. For instance, the request:
List the names of all students
is translated to SQL:
SELECT student.name
FROM ed.student;
Indeed, one may claim that the structure of the SQL query:
SELECT ...
FROM ...
WHERE ...
directly reflects the respective structure of the business inquiry.
However that correspondence falls apart when examples become more complicated. Consider an inquiry:
For each department, show the department name and the campus where it is located.
Here are some examples using our sample database:
What’s important in this form is that the business request clearly separates selection of the row set (students, schools, program degrees) and selection of the columns to output (student name, degree, number of programs, etc. I believe for many people SQL is confusing and hard to use because it does not respect this separation.
On the first sight, it is incorrect. For instance, the request:
“List the names of all schools in the north campus”
is translated to
SELECT school.name
FROM ad.school
WHERE school.campus = 'north';
and here SQL clauses directly correspond to distinct parts of the request: SELECT chooses the output column and FROM specifies the row set.
However when the request is changed slightly:
“Give me the name and the degree of each student”
the respective SQL
SELECT student.name, program.degree
FROM ed.student
JOIN ad.program ON (student.school = program.school AND
student.program = program.code)
loses this correspondence: now the FROM clause is responsible both for the row set and output column selection. Contrast this with the equivalent HTSQL query:
/student{name, program.degree}
It is not only shorter, but also the names of the tables are located in semantically meaningful positions: student in the leading position shows that every row of the output is associated with a distinct record from student table; iphdr appears in the selector to display a linked record from iphdr table (and the link event->iphdr is singular, otherwise the query would produce an error).
This effect becomes even more apparent in queries with aggregates. Compare
SELECT signature.sig_name, COUNT(*) FROM signature JOIN event ON (signature.sig_id = event.signature) GROUP BY signature.sig_id, signature.sig_name
with
/signature{sig_name, count(event)}
Note that I could easily read back the original business request out of the HTSQL variant even if I don’t know the schema, but to do the same with SQL, I need to put some effort – because the row set of the request is not manifested clearly in SQL. To determine the row set from SQL, I need to analyze the whole query: SELECT clause for DISTINCT indicator and aggregate calls, FROM clause where some tables may contribute to the row selection and the others may not, GROUP BY clause for projections.
With clear distinction between row and column selection, HTSQL achieves the level of composability impossible in SQL. For instance, the query
/signature{sig_id, count(event)}
could be easily adapted to include extra columns:
/signature{sig_id, sig_name, count(event), count(sig_reference)}
or to add a filter
/signature{sig_id, count(event)}?sig_class.sig_class_name~’protocol’
and these changes are local to the respective operations while making similar changes to SQL usually requires modifying the query all over the place.